
线程池的基本结构
线程池的基本结构,如下图所示。用户通过使用线程池的execute方法将Runnable提交到线程池中进行执行。当线程池中的线程都很忙的时候,这个新加入的 Runnable 就会被放到等待队列。当线程空闲下来的时候,就会去等待队列里查看是否还有排队等待的任务。如果有,就会队列中取出任务并继续执行。反之,线程就会进入休眠。
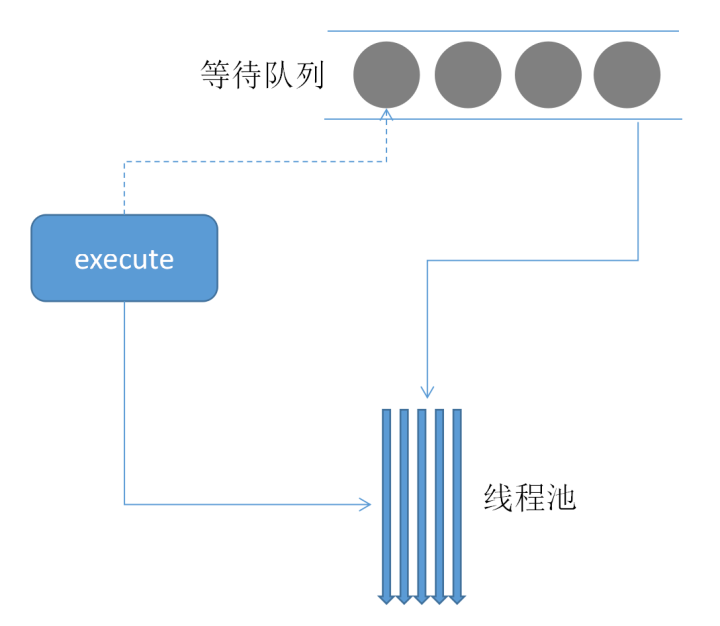
当我们把一个Runnable交给线程池去执行的时候,这个线程池处理的流程是这样的:
- 先判断线程池中的核心线程们是否空闲。如果空闲,就把这个新的任务指派给某一个空闲线程去执行。如果没有空闲,并且当前线程池中的核心线程数还小于 corePoolSize,那就再创建一个核心线程。
- 如果线程池的线程数已经达到核心线程数,并且这些线程都繁忙,就把这个新来的任务放到等待队列中去。
- 如果等待队列又满了,那么查看一下当前线程数是否到达maximumPoolSize,如果还未到达,就继续创建线程。如果已经到达了,就交给RejectedExecutionHandler来决定怎么处理这个任务。
我们通过代码来验证一下上面讲的内容:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}看上去应该是一致的。
工作线程和等待队列
工作线程里的逻辑都封装在Worker这个内部类里了。代码如下所示:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}关于锁和并发的问题,我们先不去管他。这段代码里有几个地方要注意的,第一,我们可以使用beforeExecute和afterExecute这两个方法去监控任务的执行情况。这些方法在ThreadPoolExecutor里都是空方法,我们可以重写这些方法来实现线程池的监控。第二,就是线程的逻辑是不断地执行一个循环,去调用 getTask 方法来获得任务(第一个任务是firstTask,这个请大家自己去看,我就不讲了)。所以这个getTask有必要研究一下:
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}这个方法里,前边的计数逻辑。我们先不看,这个方法的核心点在于workQueue.poll,workQueue的类型是
private final BlockingQueue workQueue; 这是一个阻塞队列!这就意味着,如果某一个线程试图从这个队列中取数据,而这个队列里没有数据的时候,线程就会进入休眠了。
至于前边的那些逻辑,加加减减的并不重要,感兴趣的可以自己查看这个方法的注释。总而言之,就是返回一个null,让worker线程退出。所以,getTask里能返回 null 的分支都是满足线程退出条件的。
RejectedExecutionHandler
当队列和线程池都满了的时候,再有新的任务到达,就必须要有一种办法来处理新来的任务。Java线程池中提供了以下四种策略:
- AbortPolicy: 直接抛异常
- CallerRunsPolicy:让调用者帮着跑这个任务
- DiscardOldestPolicy:丢弃队列里最老的那个任务,执行当前任务
- DiscardPolicy:不处理,直接扔掉
例如,我们看一个例子:
public static class CallerRunsPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code CallerRunsPolicy}.
*/
public CallerRunsPolicy() { }
/**
* Executes task r in the caller's thread, unless the executor
* has been shut down, in which case the task is discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}这个例子就是,如果线程池和队列都满了,那做为调用者。您就自己去执行 r.run 吧,我线程池是不管了。您爱咋咋滴。另外,让调用者去自己执行,也可以让调用者不要再往线程池里放任务了,有帮于减轻线程池的压力。