
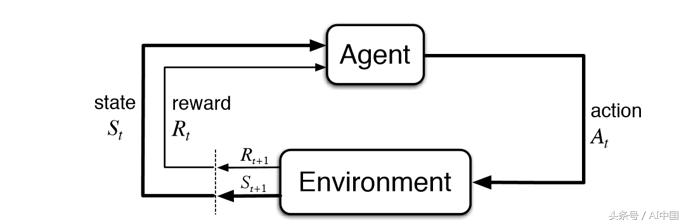
你现在正在阅读的第一部分将解释RL(强化学习)是什么以及为什么它从根本上是有一些缺陷的。它将包含一些可以被AI从业者忽略的解释,但是一定要坚持讨论最近的非纯粹RL工作,我们认为这些解释代表了对纯RL的基本缺陷的修复。首先,让我们先从一个有趣的故事开始吧。
棋盘游戏的故事
想象一下:你的朋友邀请你玩一个你从未玩过的棋盘游戏。事实上,在你的生活中,你从未玩过棋盘游戏,也没有玩过任何类型的游戏。你的朋友告诉你有效的动作是什么,但不会告诉你它们是什么意思,也不会告诉你比赛的得分方式。所以,没有更多的问题、解释就已经开始玩了。可能在前期的过程中,你会一直在游戏中输,但是经过几周的连续比赛和数千场比赛,你甚至可以勉强获胜。
看起来好像有点傻,对吗?你为什么不问这个游戏的目标是什么以及应该怎么玩?然而,上面这段描述了大多数强化学习方法在今天仍然有效。
强化学习(RL)是AI中的基本子域之一。在RL框架中,代理与环境交互以了解在任何给定环境状态下需要采取哪些操作以最大化其长期奖励。在棋盘游戏的故事中,这意味着让您与棋盘互动,慢慢您才能够了解您应该在每个棋盘游戏配置中采取什么动作以最大化您的最终得分。
在RL的典型模型中,代理仅在知道可能的行为的情况下开始,它对世界一无所知,并期望通过与环境互动并在每次采取行动后获得奖励来学习技能。缺乏先验知识意味着代理人需要“从头开始”学习。让我们将这种从头开始学习的方法称为纯粹的RL。纯粹的RL特别用于处理backgammon和围棋等游戏,以及机器人等其他地方的各种问题。

在棋盘游戏故事中,“一集”将是一个完整的游戏。在这个例子中,许多RL问题,只有最后一个状态的奖励是非零的。
AlphaGo 0和AlphaZero——纯RL模式学习围棋、国际象棋比人类完成的效果要好。
RL的研究最近通过深度学习重新焕发活力,但基本模型并未发生太大变化,毕竟,这种从头开始学习的方法可以追溯到RL作为研究领域的创造,并被编码在其最基本的方程中。
所以这里有一个基本问题:如果纯粹的RL具有如此直观的感觉,那么基于纯RL设计AI模型有多合理?如果设想人类通过纯粹的RL学习新的棋盘游戏是如此荒谬,我们难道不应该怀疑它是否是AI代理人应该学习的有缺陷的框架?既没有先前经验也没有更高级别的指导,仅根据其奖励信号就开始学习新技能是否真的有意义呢?
从经典用于形式化RL的方程中完全没有先前经验和高级指令,并且隐式或显式地改变这些方程可能对我们用于训练所有RL应用的AI算法的算法有很大的影响。(远远超出棋盘游戏,从机器人到资源分配)。换句话说,这是一个大问题,回答它甚至需要两篇文章:
- 在第一部分(本文)中,我们将首先展示纯粹的RL的主要成就并不像它们看起来那么令人印象深刻。然后,我们将进一步展示在纯粹的RL下可能无法实现更复杂的成就,因为它对AI代理施加了许多限制。
- 在第二部分中,我们将概述AI中可以解决这些局限性的不同方法。最后,我们将根据这些方法对基于令人兴奋的工作进行调查,并总结一下这项工作对RL和AI整体未来的意义。
纯粹的RL实际上是否有意义?
许多人的直接反应如下:
当然,使用纯粹的RL仍然是有意义的。AI代理人不是人类,不必像我们一样学习,纯粹的RL现已被证明可以解决各种复杂的问题。
作者不同意这个看法。根据定义,人工智能研究涉及到使机器能够做人类和动物目前能够做的事情的雄心。因此,我们还常会把它与人类的智力进行比较。至于纯粹的RL已被用来解决的问题。
这对许多人来说可能是一个惊喜,因为解决这些问题一直是人工智能最广为人知的成就的源泉。虽然这些确实是很大的成就,但我仍然声称所涉及的问题并不像它们看起来那么复杂。在讨论为什么会这样之前,让我们列举一下这些成就,并指出为什么它们绝对值得称赞:
- DQN-- DeepMind的研究项目,通过展示将深度学习与纯粹的RL和一些新的创新相结合,能够解决比以往更复杂的问题,在短短5年前就对RL研究的兴趣大大增加。
可以毫不夸张地说,DQN是一手恢复研究人员对RL的兴趣的模型。虽然它只包含了一些相对简单的创新,但这些创新对于使'Deep RL’变得实用非常重要。
因为它不再从人类那里学到成功,所以AlphaGo Zero被许多人认为比AlphaGo更能改变游戏规则。然后是AlphaZero,这是一个更通用的版本,不仅可以解决Go,还可以解决Chess和Shogi等游戏,这是第一次使用单一算法来破解国际象棋和围棋,并且没有专门针对深蓝和原版AlphaGo等游戏进行定制。由于上述所有原因,AlphaGo Zero和AlphaZero无疑是具有纪念意义且令人兴奋的成就。
OpenAI的Dota机器人——深度RL驱动的人工智能代理,可以在流行且复杂的竞争多人游戏Dota 2中击败人类。OpenAI 2017年在有限的1对1版本的游戏中击败职业玩家的成就令人印象深刻,但与他们相比,最近的一项壮举是在一场更加复杂的5对5游戏中击败了一支人类球员。它也是AlphaGo Zero的继承者,因为它不需要任何人类知识,纯粹通过自我游戏进行训练。 OpenAI自己很好地解释了他们的成就:
毫无疑问,在这种以团队合作为基础的高度复杂的游戏中取得好成绩远远超过击败Atari游戏和Go的先前成就。更重要的是,这是在没有任何重大算法进步的情况下完成的。这一成就归功于真正惊人的计算量和使用已经建立的纯RL算法以及深度学习。在人工智能社区中,有一个共同的印象,这是一项令人印象深刻的成就,也是RL一系列重要里程碑的下一步:
是的,纯粹的RL已经取得了很多成就。但现在让我们仔细看看为什么这些成就可能不像看起来那么令人印象深刻。
论RL近期成功的复杂性
让我们从DQN开始吧。
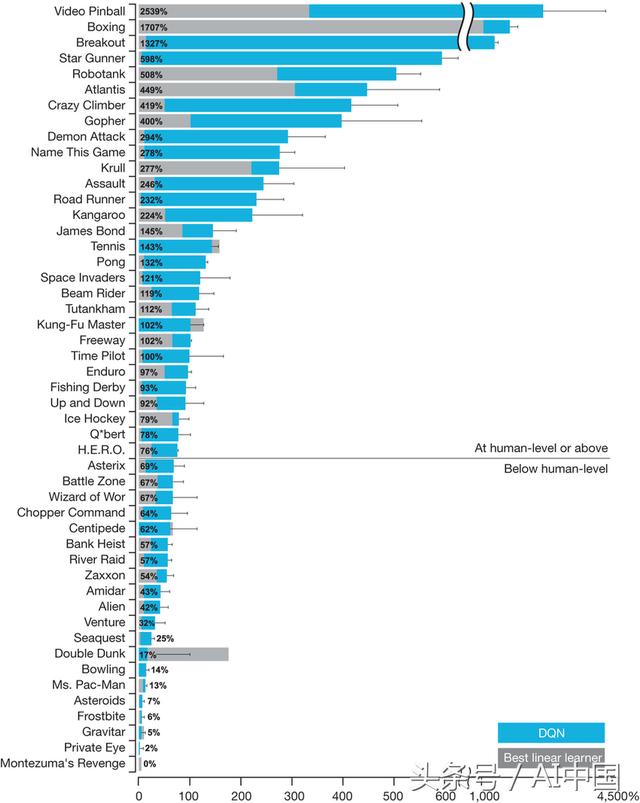
尽管DQN在像Breakout这样的游戏中很出色,但它仍然无法解决像Montezuma的Revenge这样相对简单的游戏。
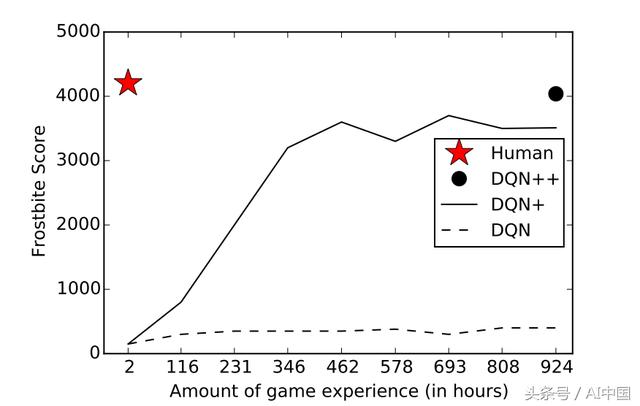
- 即使对于DQN可以非常好的游戏,与人类相比,它还是需要的大量时间和经验来学习。
AlphaGo Zero和AlphaZero也有同样的限制。你看,Go在最简单的AI问题类别的背景下很难。也就是说,在每个属性的问题类别中,使学习任务变得容易:它是确定性的、离散的、静态的、完全可观察的、完全已知的、单一代理的、情节的、便宜且易于模拟的......对Go来说,只有一件事是挑战:它的巨大分支因素。
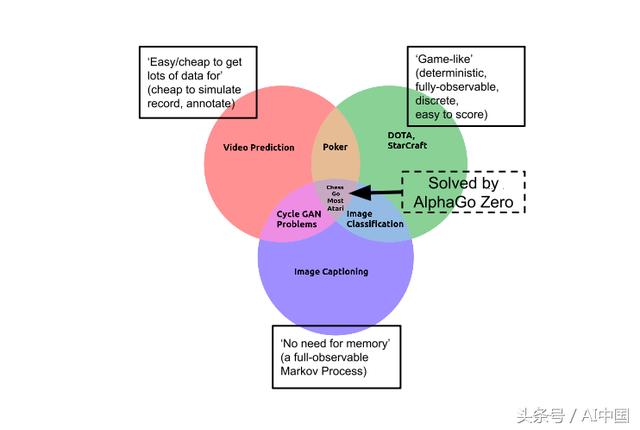
因此,Go可能是最难的问题,但它仍然是一个容易出问题的地方。由于上述所有原因,大多数研究人员认识到现实世界比像Go这样的简单游戏要复杂得多。虽然令人印象深刻,AlphaGo的所有变体仍然与深蓝基本类似:它是一个昂贵的系统,经过多年设计,投入数百万美元,纯粹是为了玩抽象棋盘游戏的任务,而不是别的。
到Dota,是的,这是一个比Go复杂得多的游戏,缺少许多让Go变得简单的属性。它不是离散的,静态的,完全可观察的,单一的代理或偶发的,它是一种极具挑战性的问题。但它仍然是一个易于模拟的游戏,通过一个漂亮的API控制,可以完全消除需求感知或电机控制,所以最终会很简单,相比于学习解决现实世界中的问题的真正复杂性,它仍然像AlphaGo一样,需要大量投资和许多工程师使用大量时间和经验来获得算法来解决问题。
因此,尽管取得了巨大的成就,但对于所有人来说,还是有一些强烈的警告要注意。仅仅因为RL已经走了这么远就认为纯RL是好的是不正确的。所有这一切,必须考虑纯粹的RL是否只是第一个取得巨大的成绩,但不一定最好的方式。
纯粹的 RL 的根本缺陷 - 从零开始
可能有更好的方式让AI代理人学习玩Go或Dota吗?名称“AlphaGo Zero”是指模型学会了“从头开始”。但让我们回想一下棋盘游戏的故事,试图在没有解释的情况下“从零开始”学习棋盘游戏,这是很荒谬的,对吧,那么为什么要努力实现AI呢?
事实上,如果你想要学习的棋盘游戏是Go,你将如何开始学习呢?你会阅读规则,学习一些高级策略,回想起你过去玩过的类似游戏的方式,得到一些建议......对吗?事实上,至少部分是因为AlphaGo Zero和OpenAI的Dota机器人从零开始限制学习,它与人类学习相比并不真正令人印象深刻:它们依赖于看到更多数量级的游戏。
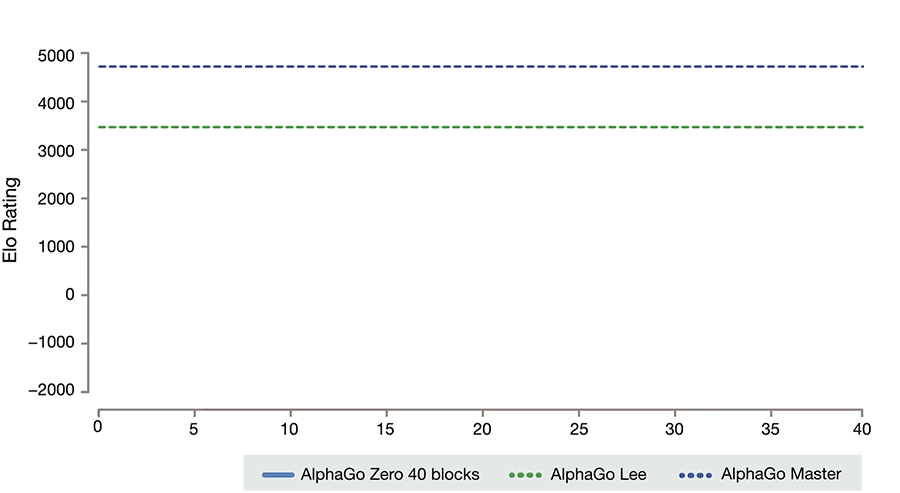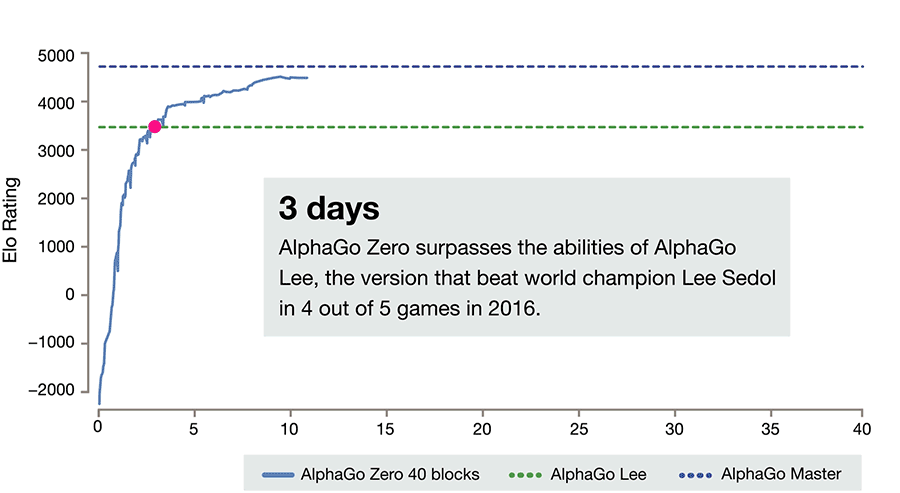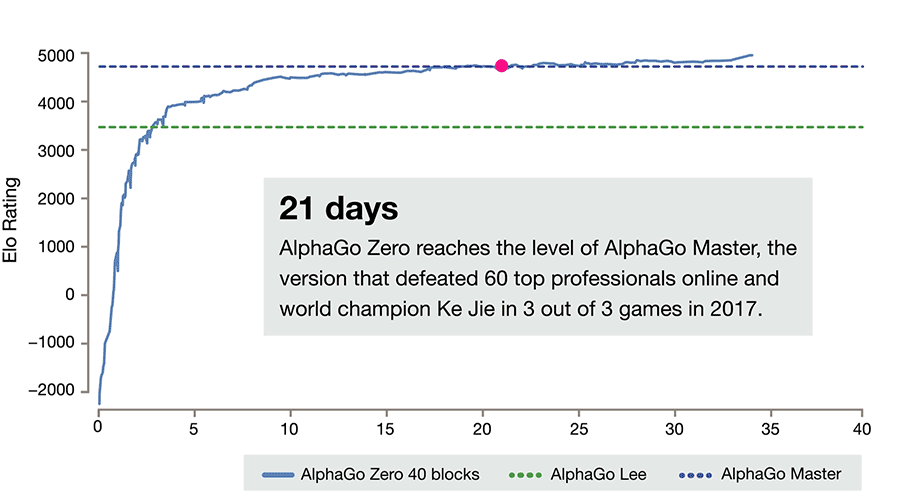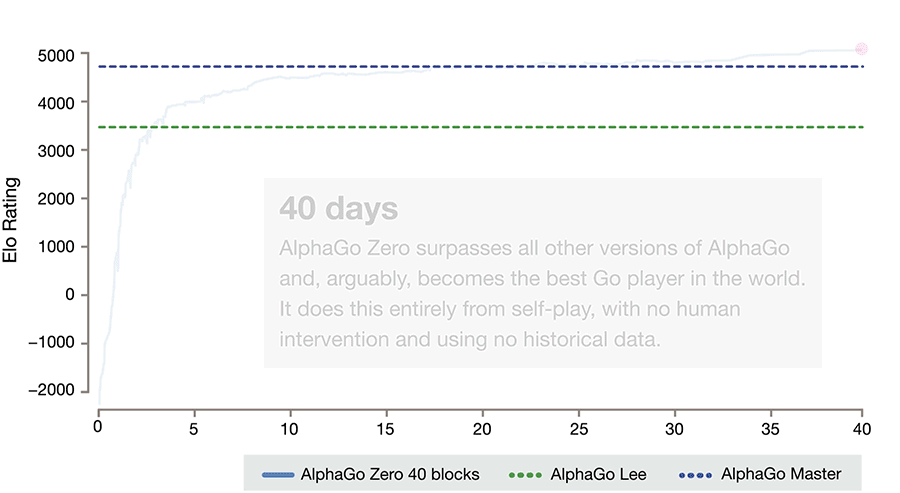
公平地说,纯粹的RL技术可以合法地用于“狭窄”的任务,如Dota或星际争霸。然而,随着深度学习的成功,人工智能研究团体现在正在努力解决日益复杂的任务,这些任务必须处理现实世界中无限的复杂性(例如自动驾驶)问题。这是针对这些不那么狭隘的任务(即AI需要解决的大多数问题),以及AI作为一个整体的长期未来,超出纯粹的RL可能是必要的。
我们应该坚持纯粹的RL吗?
这个问题的一个答案可能是:
是的,纯粹的RL是解决Go或Dota等问题的正确方法。虽然在棋盘游戏中没有任何意义,但一般来说,从头开始学习东西确实很有意义。而且,除了人类的灵感之外,从头开始是有意义的,因此代理没有先入之见,可能会比我们更好(就与AlphaGo Zero一样)。
让我们回到人类学习的问题,从头开始学习。人们是否开始学习一项复杂的新技能,除了他们作为该技能的一部分可能采取的行动之外,没有任何信息。

也许对于一些非常基本和普遍的问题(例如年幼的婴儿处理的问题),从头开始做纯RL是有道理的,因为这些问题是如此广泛,所以很难做任何其他事情。但对于AI中的绝大多数问题,从头开始并没有明显的好处。事实上,从头开始是许多广泛认可的当前AI和RL限制的主要原因:
- 当前的AI需要大量数据(即样本效率低下 - 在大多数情况下,需要大量数据才能使用最先进的AI方法。这对于纯RL技术尤为重要,回想一下AlphaGo Zero需要数百万Go的游戏得到的ELO得分为0,大多数人都会立即管理。根据定义,从头开始学习可能是最不具有样本效率的方法)。
- 当前的AI是不透明的。在大多数情况下,我们对AI算法学习的内容及其工作方式只有高层次的直觉。对于大多数AI问题,我们希望算法是可预测和可解释的,只有低水平的奖励信号和环境模型(AlphaGo Zero如何工作)才能从头开始学习任何想要的东西,这是一种可学习的最不可解释和可预测的学习方法。
- 当前的AI很窄,在大多数情况下,我们构建的AI模型只能执行一个非常狭窄的任务,并且很容易被破坏。从头开始学习每一项技能都限制了学习任何东西的能力。
- 目前的AI很脆弱,在大多数情况下,我们的AI模型只能通过大量数据很好地推广到不可见的输入,甚至还可以轻松地打破。
因此,我们倾向于知道我们希望AI代理学习什么。如果AI代理是一个人,我们可以解释任务,并可能提供一些提示。但AI代理人不是人,我们可能会为AI代理人这样做吗?