
Web 安全的定义
随着 Web 2.0、社交网络、微博等等一系列新型的互联网产品的诞生,基于 Web 环境的互联网应用越来越广泛,企业信息化的过程中各种应用都架设在 Web 平台上,Web 业务的迅速发展也引起黑客们的强烈关注,接踵而至的就是 Web 安全威胁的凸显,黑客利用网站操作系统的漏洞和 Web 服务程序的 SQL 注入漏洞等得到 Web 服务器的控制权限,轻则篡改网页内容、重则窃取重要内部数据,更为严重的则是在网页中植入恶意代码,使得网站访问者受到侵害。
根据 2017 年度发布的中国网络安全报告来看,Web 安全现状不容乐观啊;以下是一些必要的Web安全知识,我与各位共勉。
了解渗透测试
什么是渗透测试?
渗透测试,是为了证明网络防御按照预期计划正常运行而提供的一种机制。不妨假设,你的公司定期更新安全策略和程序,时时给系统打补丁,并采用了漏洞扫描器等工具,以确保所有补丁都已打上。如果你早已做到了这些,为什么还要请外方进行审查或渗透测试呢?因为,渗透测试能够独立地检查你的网络策略,换句话说,就是给你的系统安了一双眼睛。而且,进行这类测试的,都是寻找网络系统安全漏洞的专业人士。
渗透测试,较为通俗的说法就是模拟黑客的攻击去测试计算机网络安全的一种方法。从事渗透测试的安全人员,在不同的的位置(外网、内网等)用某种特定的手段对某个特定地址来进行安全测试。发现网络中存在的安全漏洞,接着写“渗透测试报告文档”并提交给该网络管理员,网络管理员可以从“渗透测试报告文档”中清楚的查看到系统所存在的安全漏洞以及修复方案。
渗透测试者尽可能完整的模拟黑客的攻击方法,对目标网络、系统、主机、应用程序的安全性做深入的测试,来发现系统最薄弱的环节。
为什么要执行渗透测试?
在有的管理员看来,不必要花钱去测试一次安全服务,因为 Web 漏洞扫描器扫描出的结果是不存在安全问题的,但是结果恰恰相反,有的时候,Web 漏洞扫描器可不那么灵,隐藏在逻辑中的安全问题,就不是 Web 漏洞扫描器所能检测到的地方。
打个比方来说,你要修建一家牢固无比的金库,按照设计蓝图一家修好了,那么此时是否就可以投入使用了呢?肯定不存在,因为你不知道这个金库的安全性如何,没有投入实践、没有风险方案,那么怎么去保证金库里面的资产安全呢?正确的做法就应该是在投入使用之前,请一些专家来进行一次模拟风险的一次攻击,来测试你的金库大门是否真正的安全。
安全行业的渗透测试也如银行的金库一样,需要专业人员进行系统的安全测试,来验证安全性。渗透测试可以促使许多企业管理人员减少损失或者是减少威胁。
渗透测试评估系统的安全须是长期性的、定时的测试,原因在于现在很多的企业业务线拉的非常长,加上还有外包的因素,导致开发人员水平不齐,造成漏洞的出现。
渗透测试的流程?
渗透测试人员在实施渗透测试的过程中多会使用漏洞扫描器,工具会使渗透测试流程中时间大大缩小,同时会把网络拓扑结构、程序信息理清,使一些部分成为自动化,但仅仅是使用工具是完全不够的,因为工具存在误报的情况,有时候需要人工手动逐一排查问题。
渗透测试流程基本都遵从 PTES(Penetration Testing Execution Standard)渗透测试执行标准是安全业界在渗透测试技术领域中正开发的一个新标准,目标是在对渗透测试进行重新定义,新标准的核心理念是通过建立起进行渗透测试所要求的基本准则基线,来定义一次真正的渗透测试过程,并得到安全业界的广泛认同。
PTES 包含了七个阶段。
前期交互阶段
在前期交互(Pre-Engagement Interaction)阶段,渗透测试团队与客户组织进行交互讨论,最重要的是确定渗透测试的范围、目标、限制条件以及服务合同细节。
情报收集阶段
在目标范围确定之后,将进入情报搜集(Information Gathering)阶段,渗透测试团队可以利用各种信息来源与搜集技术方法,尝试获取更多关于目标组织网络拓扑、系统配置与安全防御措施的信息。
渗透测试者可以使用的情报搜集方法包括公开来源信息查询、Google Hacking、社会工程学、网络踩点、扫描探测、被动监听、服务查点等。而对目标系统的情报探查能力是渗透测试者一项非常重要的技能,情报搜集是否充分在很大程度上决定了渗透测试的成败,因为如果你遗漏关键的情报信息,你将可能在后面的阶段里一无所获。
威胁建模阶段
在搜集到充分的情报信息之后,渗透测试团队的成员们停下敲击键盘,大家聚到一起针对获取的信息进行威胁建模(Threat Modeling)与攻击规划,这是渗透测试过程中非常重要,但很容易被忽视的一个关键点。
通过团队共同的缜密情报分析与攻击思路头脑风暴,可以从大量的信息情报中理清头绪,确定出最可行的攻击通道。
漏洞分析阶段
在确定出最可行的攻击通道之后,接下来需要考虑该如何取得目标系统的访问控制权,即漏洞分析(Vulnerability Analysis)阶段。
在该阶段,渗透测试者需要综合分析前几个阶段获取并汇总的情报信息,特别是安全漏洞扫描结果、服务查点信息等,通过搜索可获取的渗透代码资源,找出可以实施渗透攻击的攻击点,并在实验环境中进行验证。在该阶段,高水平的渗透测试团队还会针对攻击通道上的一些关键系统与服务进行安全漏洞探测与挖掘,期望找出可被利用的未知安全漏洞,并开发出渗透代码,从而打开攻击通道上的关键路径。
渗透攻击阶段
渗透攻击(Exploitation)是渗透测试过程中最具有魅力的环节。在此环节中,渗透测试团队需要利用他们所找出的目标系统安全漏洞,来真正入侵系统当中,获得访问控制权。
渗透攻击可以利用公开渠道可获取的渗透代码,但一般在实际应用场景中,渗透测试者还需要充分地考虑目标系统特性来定制渗透攻击,并需要挫败目标网络与系统中实施的安全防御措施,才能成功达成渗透目的。在黑盒测试中,渗透测试者还需要考虑对目标系统检测机制的逃逸,从而避免造成目标组织安全响应团队的警觉和发现。
后渗透攻击阶段
后渗透攻击(Post Exploitation)是整个渗透测试过程中最能够体现渗透测试团队创造力与技术能力的环节。前面的环节可以说都是在按部就班地完成非常普遍的目标,而在这个环节中,需要渗透测试团队根据目标组织的业务经营模式、保护资产形式与安全防御计划的不同特点,自主设计出攻击目标,识别关键基础设施,并寻找客户组织最具价值和尝试安全保护的信息和资产,最终达成能够对客户组织造成最重要业务影响的攻击途径。
在不同的渗透测试场景中,这些攻击目标与途径可能是千变万化的,而设置是否准确并且可行,也取决于团队自身的创新意识、知识范畴、实际经验和技术能力。
报告阶段
渗透测试过程最终向客户组织提交,取得认可并成功获得合同付款的就是一份渗透测试报告(Reporting),这份报告凝聚了之前所有阶段之中渗透测试团队所获取的关键情报信息、探测和发掘出的系统安全漏洞、成功渗透攻击的过程,以及造成业务影响后果的攻击途径,同时还要站在防御者的角度上,帮助他们分析安全防御体系中的薄弱环节、存在的问题,以及修补与升级技术方案。
实施渗透测试扫描过程中需要遵守以下几个原则
- 标准性原则:漏洞扫描的方式需要遵守相关规定。
- 规范性原则:扫描过程中所记录的文档应有良好的写作格式,需清楚的记录所用工具以及扫描策略。
- 可控性原则:在扫描过程中,需要保证对漏洞扫描工作的可控性。漏洞扫描的方式和策略应该要在双方认可之内的范围内进行。
- 整体性以及不可缺原则:在扫描的过程中所扫描的内容应该包括用户等各个层面,漏洞扫描的对象不可脱离用户指定范围的设备系统,未经允许不可擅自修改扫描范围和对象。
- 影响性原则:漏洞扫描工作不可让系统或者网络中断,应在系统业务量较小的时段对系统进行漏洞扫描工作,尽量不对系统或者网络造成破坏,做到影响性最小。
- 保密原则:漏洞扫描的过程和结果应该严格保密,不可泄露其有效数据文件。
渗透测试分类
现在普遍认同的渗透测试种类包含了两种,他们分别是黑盒测试和白盒测试。
黑盒测试
黑盒测试又被称为所谓的“Zero-Knowledge Testing”,渗透者完全处于对系统一无所知的状态,通常这类型测试,最初的信息获取来自于 DNS、Web、Email 及各种公开对外的服务器。
白盒测试
白盒测试与黑箱测试恰恰相反,测试者可以通过正常渠道向被测单位取得各种资料,包括网络拓扑、员工资料甚至网站或其他程序的代码片断,也能够与单位的其他员工(销售、程序员、管理者……)进行面对面的沟通。这类测试的目的是模拟企业内部雇员的越权操作。
黑盒模拟的完全是对目标系统完全一无所知的情况,而白盒测试则是可以向被测单位索要信息资料和代码,以提供后面的代码审计服务,两者差距较大,所以黑盒测试是最能模拟真实环境的一种渗透测试方法。
目标分类
- 主机操作系统渗透:对 Windows、Solaris、AIX、Linux、SCO、SGI 等操作系统本身进行渗透测试。
- 数据库系统渗透:对 MS-SQL、Oracle、MySQL、Informix、Sybase、DB2、Access 等数据库应用系统进行渗透测试。
- 应用系统渗透:对渗透目标提供的各种应用,如 ASP、CGI、JSP、PHP 等组成的 WWW 应用进行渗透测试。
- 网络设备渗透:对各种防火墙、入侵检测系统、网络设备进行渗透测试。
已授权的渗透测试流程
对于已授权的渗透测试流程如下:
- 拿到授权书
- 查看授权书内容
- 收集信息并整理
- 对目标系统进行漏洞扫描
- 攻击
- 输出渗透测试报告文档
- 未授权的渗透测试流程
- 信息收集
- 漏洞扫描并测试
- 清理入侵痕迹
- 输出渗透测试报告文档
两者区别不大,但是未授权的渗透测试需要清理痕迹,另外“渗透测试”和“渗透”有区别的地方在于:渗透测试的目的的做一个渗透测试,但是并不去利用漏洞或者破坏系统,而渗透则没有明确目与规定。
Kali Linux 渗透测试平台的安装
什么是 Kali Linux?
Kali Linux 是为 Hacker 设计的,里面内置了大量的渗透类的工具,在最新版本已经包含了大概 600 多个安全工具,所以在以后的课程里,我们都会用到这个系统来进行渗透测试实验。
Kali Linux 是基于 Debian 系统的发行版,与此类似的还有著名的乌班图(Ubuntu)系统,用过 Linux 的读者都应该能快速上手,安装方法非常的简单,官网有 VM 虚拟机镜像,打开就能使用了,因此这里只写个大概安装过程。
Kali Linux 的官方在信息安全界还有一个含金量非常高的考试,Kali 渗透测试(Pentesting with Kali)认证。该认证的申请者必须在艰难的 24 小时内成功入侵多台计算机,然后另外 24 小时内完成渗透测试报告并发送给 Offensive Security 的安全人员进行评审,成功通过考试的人将会获得 OSCP 认证证书。
Kali Linux 安装比较简单,直接去官网下载即可;
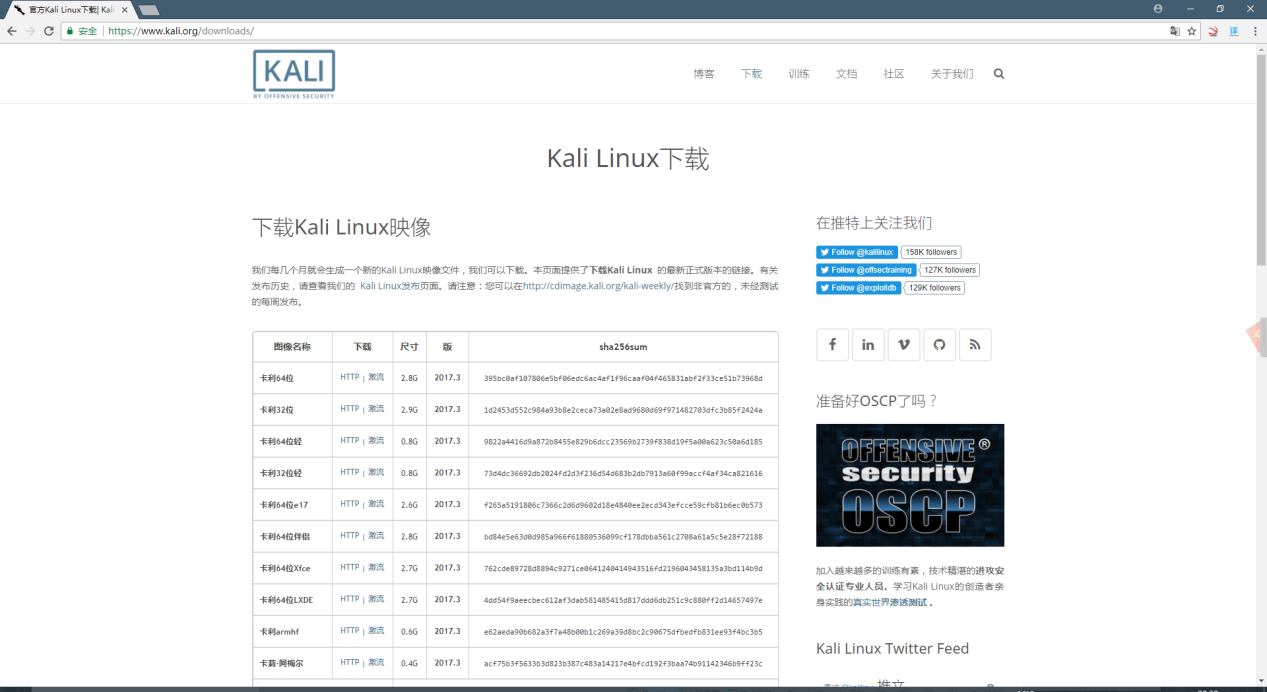
如图上所示,下载最新版的 Kali Linux 64 位即可,请注意它是一个 ISO 文件,也可以将其复制到 USB 便携式设备中。
安装 Kali Linux 系统
首先,把 USB 设备插入到要安装 Kali 操作系统的电脑上,然后从 USB 设备引导系统启动。只要成功地从 USB 设备启动系统,将会看到下面的图形界面,选择“Install”或者“Graphical Install”选项。
本指南将使用“Graphical Install”方式进行安装。

Kali Linux 启动菜单
下面几个界面将会询问用户选择区域设置信息,比如语言、国家,以及键盘布局。选择完成之后,系统将会提示用户输入主机名和域名信息,输入合适的环境信息后,单击“继续”安装按钮。
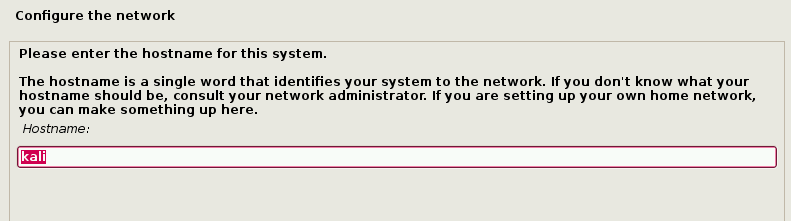
设置 Kali Linux 系统的主机名。
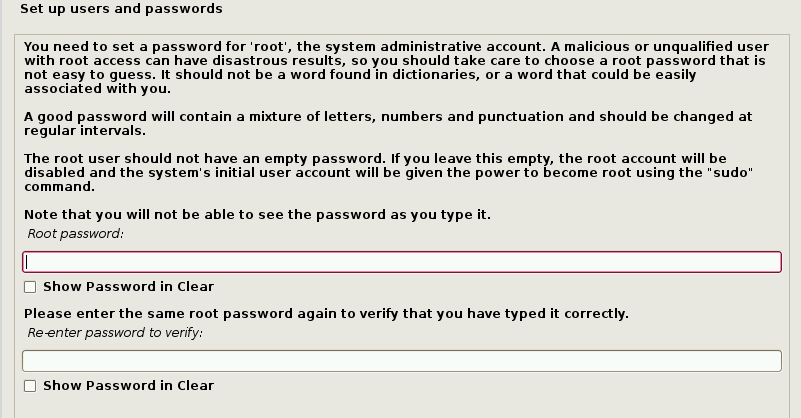
设置 Kali Linux 系统用户密码。
密码设置完成之后,安装步骤会提示用户选择时区然后停留在硬盘分区界面。如果 Kali Linux 是这个电脑上的唯一操作系统,最简单的选项就是使用“Guided – Use Entire Disk”,然后选择你需要安装 Kali 的存储设备。
选择 Kali Linux 安装磁盘
下一步将提示用户在存储设备上进行分区。大多数情况下,我们可以把整个系统安装在一个分区内。
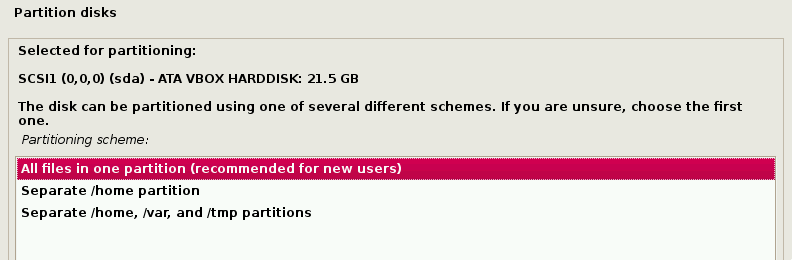
后一步引导 Grub 后即可完成安装,安装过程基本都是全程回车到结束,十分简单。
Kali Linux 安装之后的配置
添加官方软件库。
(1)编辑 /etc/apt/sources.list,leafpad /etc/apt/sources.list
(2)用 # 注释掉原有的内容,并添加下述内容:
# Regular repositoriesdeb http://http.kali.org/kali sana main non-free contribdeb http://security.kali.org/kali-security sana/updates main contrib non-free#Source repositoriesdeb-src http://http.kali.org/kali sana main non-free contribdeb-src http://security.kali.org/kali-security sana/updates main contrib non-free
3)顺序执行下列命令:
- apt-get update
- apt-get upgrade
- apt-get dist-upgrade
对 Kali Linux 系统进行升级,保持最新版本,另外升级的时候速度慢,请找梯子或者替换源为中科大的源,速度很快。
HTTP 请求详解
什么是 HTTP 协议
只要客户端和 Web 服务器进行交互时,就存在 Web 请求,这种请求就是 HTTP 协议的相互交互数据。
一次完整的 HTTP 请求过程从 TCP 三次握手建立连接成功后开始,客户端按照指定的格式开始向服务端发送 HTTP 请求,服务端接收请求后,解析 HTTP 请求,处理完业务逻辑,最后返回一个 HTTP 的响应给客户端,HTTP 的响应内容同样有标准的格式。无论是什么客户端或者是什么服务端,大家只要按照 HTTP 的协议标准来实现的话,那么它一定是通用的。
HTTP 请求组成
HTTP 请求格式主要有四部分组成,分别是:请求行、请求头、请求正文,每部分内容占一行。
下面是一个 HTTP 请求的一个例子:
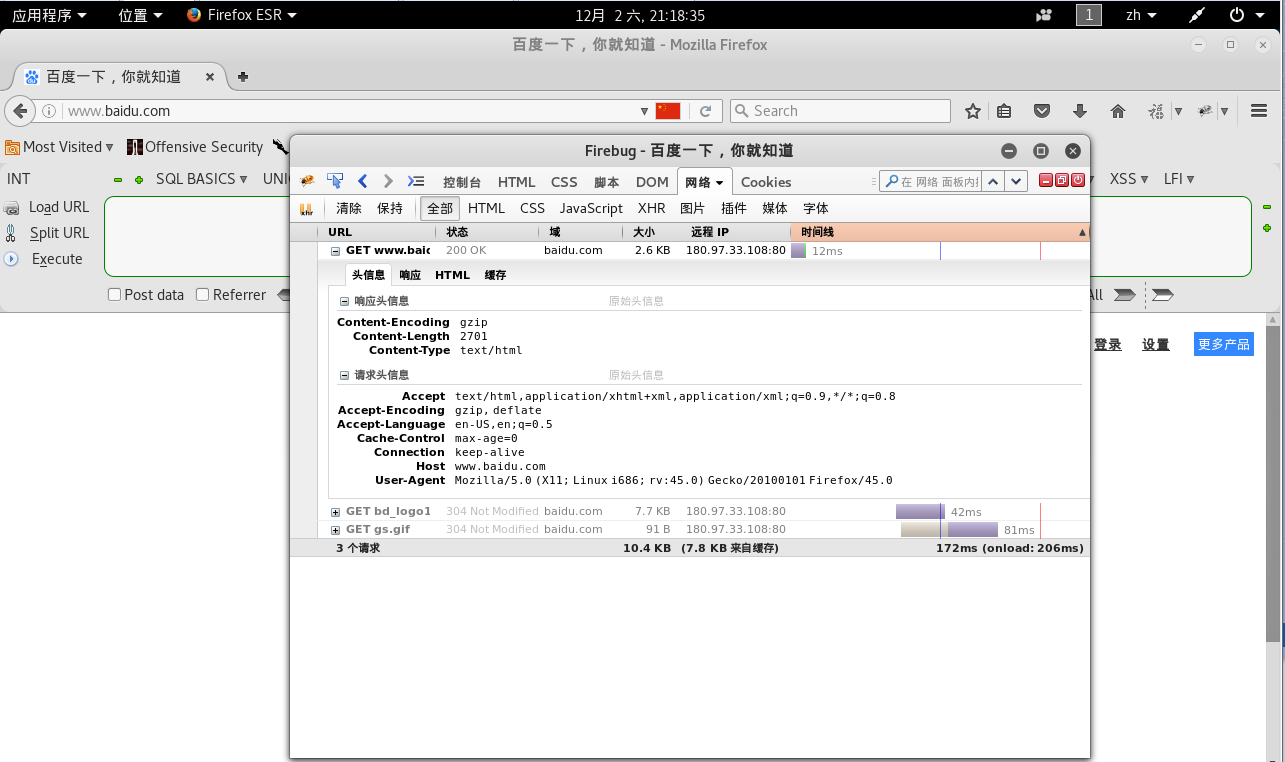
GET / HTTP/1.1 //请求行 Host: www.baidu.com //请求头 User-Agent: Mozilla/5.0 (X11; Linux i686; rv:45.0) Gecko/20100101 Firefox/45.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip, deflate Connection: keep-alive // 空白行,代表响应头结束 Cache-Control: max-age=0 //请求正文
HTTP 的请求行第一行就是请求行,请求行为三部分组成,第一部分说明了这个请求是 GET 请求,第二部分斜杠那里(/HTTP/)用来说明请求的是什么内容,最后一行说明使用的是 HTTP 1.1 版本协议,也有 1.0 的。
第二行和空白行就是 HTTP 中的请求头,其中的 host 请求代表请求的主机地址,User-Agent 代表的是浏览器的标识,比如 User-Agent: Mozilla/5.0 (X11; Linux i686; rv:45.0) Gecko/20100101 Firefox/45.0,就说明我是火狐浏览器,Linux 系统来做的这个请求。
HTTP 的请求的最后一行是请求正文,请求正文的内容并不是固定的,常常出现在 Post 请求中,GET 少见。
HTTP 响应
与 HTTP 请求相对,HTTP 响应就可以当做是浏览器给你的一次回复,HTTP 响应也由三部分组成,分别是响应行、响应内容和响应正文。下面是个 HTTP 响应。
HTTP/1.1 200 OK //响应行 Date: Sat, 02 Dec 2017 13:28:49 GMT //响应头 Server: Apache P3P: CP=" OTI DSP COR IVA OUR IND COM " Set-Cookie: BAIDUID=DA1513C25E1ED809E79A467DAB89EA2D:FG=1; expires=Sun, 02-Dec-18 13:28:49 GMT; max-age=31536000; path=/; domain=.baidu.com; version=1 Last-Modified: Fri, 08 Sep 2017 08:30:40 GMT Etag: "3d16-558a9645bac00" Accept-Ranges: bytes Cache-Control: max-age=86400 Expires: Sun, 03 Dec 2017 13:28:49 GMT Vary: Accept-Encoding,User-Agent Content-Encoding: gzip Content-Length: 4830 Connection: Keep-Alive //空白行,代表响应头已经结束 Content-Type: text/html //响应正文
响应行:状态行位于相应消息的第一行,有 HTTP 协议版本号,状态码和状态说明三部分构成。如:
HTTP/1.1 200 OK
响应行里包含了 HTTP 版本(HTTP/1.1)状态码(200)以及响应(OK),OK 即代表请求成功,响应给了你回复。
响应头和 HTTP 请求是一样的,这里不解释了。
响应正文便是服务端收到你这个请求之后,朝你的客户端发送的 HTML 数据。
HTTP 请求方法
HTTP 请求方法有很多,共计 15 种,但是这里只解释常用的请求方法。
- GET 请求指定的页面信息,并返回实体主体。
- HEAD 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头。
- POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。
- PUT 从客户端向服务器传送的数据取代指定的文档的内容。
- DELETE 请求服务器删除指定的页面。
- CONNECT HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
- OPTIONS 允许客户端查看服务器的性能。
- TRACE 回显服务器收到的请求,主要用于测试或诊断。
- PATCH 实体中包含一个表,表中说明与该 URI 所表示的原内容的区别。
- MOVE 请求服务器将指定的页面移至另一个网络地址。
- COPY 请求服务器将指定的页面拷贝至另一个网络地址。
- LINK 请求服务器建立链接关系。
- UNLINK 断开链接关系。
- WRAPPED 允许客户端发送经过封装的请求。
- Extension-mothed 在不改动协议的前。
其中 GET、Post 请求方法最为常见。
GET
GET 是获取页面的指定信息,比如获取百度的一个页面(www.baidu.com/index.php?id=1):
Get / index.php?id=1 HTTP/1.1Host:www.baidu.com这是一个 GET 请求,请求的是 index.php,内容参数是1。
GET 请求也比较懒,它只接受开发者已经设置好的参数,比如开发者只设置了只接受 ID 参数内容,其他数据都是不会去收的,比如 Get / index.php?id=1&user=admin, 这末尾这串 user=admin 就不会去接收,鸟都不想鸟你这种。
GET 请求他只是获取、查询数据,也就是说它不会修改服务器上的数据,从这点来讲,它是数据安全的(仅对意义来讲是安全的)而稍后会提到的 Post 它是可以修改数据的,所以这也是两者差别之一了。
Post
Post 请求方法和 GET 有点相似,但是区别又在于,GET 请求会将发送的数据显示在浏览器端,Post 请求则不会,这样来说 Post 请求的安全性相对又高一些。
Post,它是可以向服务器发送修改请求,从而修改服务器的,比方说,我们要在论坛上回贴、在博客上评论,这就要用到 Post 了。
POST /admin/index.asp HTTP/1.1 Accept: text/html, application/xhtml+xml, image/jxr, */* Referer: http://www.baidu.com/admin/index.asp Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063 Content-Type: application/x-www-form-urlencoded Accept-Encoding: gzip, deflate Content-Length: 80 Host: www.baidu.com Pragma: no-cache Cookie: ASPSESSIONIDSQTRDBQT=EHNFDLFBJENFBNHCNHFCHCMD Connection: close admin_name=admin&admin_password=123456&admin_verifycode=3291&submit=%B5%C7%C2%BC上面这个例子就是使用了 POST 方法向服务器请求/admin/index.asp,并且在请求正文里递了参数admin_name=admin&admin_password=123456&aadmin_verifycode=3291&submi
PUT
PUT 请求方法用于请求服务器里面的内容储存在请求的资源下,如果这个资源在服务器里以及存在,那么将会用新的请求替换掉旧的内容,作为修改版保存在服务器里,如果这个资源不存在,那么将会创建资源,并且保存下来。
说简单点,GitChat 的文章保存功能就是一个 PUT 请求方法,我已经抓了下来。
PUT /writing/editor/59f027344d4d5e0d65e9074c HTTP/1.1 Origin: http://gitbook.cn Referer: http://gitbook.cn/writing/editor/59f027344d4d5e0d65e9074c Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063 Content-Type: application/json; charset=utf-8 Accept: application/json, text/javascript, */*; q=0.01 X-Requested-With: XMLHttpRequest Accept-Encoding: gzip, deflate Host: gitbook.cn Content-Length: 12594 Pragma: no-cache Cookie: 已删除 Connection: close //以下则为请求内容,已删。这是我从文章的更新和保存页面抓下来的请求。
这段 HTTP PUT 请求将会在 writing 目录下生成 editor/59f027344d4d5e0d65e9074c。不管以前的内容存不存在、有没有,都将会被这一次 PUT 请求给“刷新”掉,创建新的内容,服务器开了 PUT 请求方法挺不安全的,考虑到服务器创建文件问题。
HTTP 状态码
状态码就是前文所讲的 HTTP/1.1 200 OK。它出现在 HTTP 响应头的第一行,例子状态码是 200,代表了请求成功。HTTP 协议中的状态码都是由三位数字组成,常见的还有 404.500 等状态码,每个状态码代表了不同的响应内容。
1XX:这一类型的状态码,代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束。由于 HTTP/1.0 协议中没有定义任何 1xx 状态码,所以除非在某些试验条件下,服务器禁止向此类客户端发送 1xx 响应。
2XX:这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。
3XX:重定向状态码,这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的 Location 域中指明。
4XX:4XX 状态码也意味着客户端错误码,这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。除非响应的是一个 HEAD 请求,否则服务器就应该返回一个解释当前错误状况的实体,以及这是临时的还是永久性的状况。这些状态码适用于任何请求方法,浏览器应当向用户显示任何包含在此类错误响应中的实体内容。
5XX:类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。除非这是一个 HEAD 请求,否则服务器应当包含一个解释当前错误状态以及这个状况是临时的还是永久的解释信息实体。浏览器应当向用户展示任何在当前响应中被包含的实体。
常见的状态码如:200、404、500 等。